Jinlong Xue

Hi there! I am currently a master’s student at the Beijing University of Posts and Telecommunications (BUPT), majoring in Artificial Intelligence. I am supervised by Associate Professor Ya Li, focusing on speech synthesis, NLP, and multimodal generation.
I have a keen interest in all aspects of multimodal generation, including speech synthesis, multimodal LLM, and AIGC. I am also interested in developing intelligent and interactive AI systems with human emotions.
I plan to pursue a Ph.D. abroad after completing my master’s degree in 2025. If any professors or researchers are interested in my work or see potential for collaboration, please do not hesitate to contact me!
news
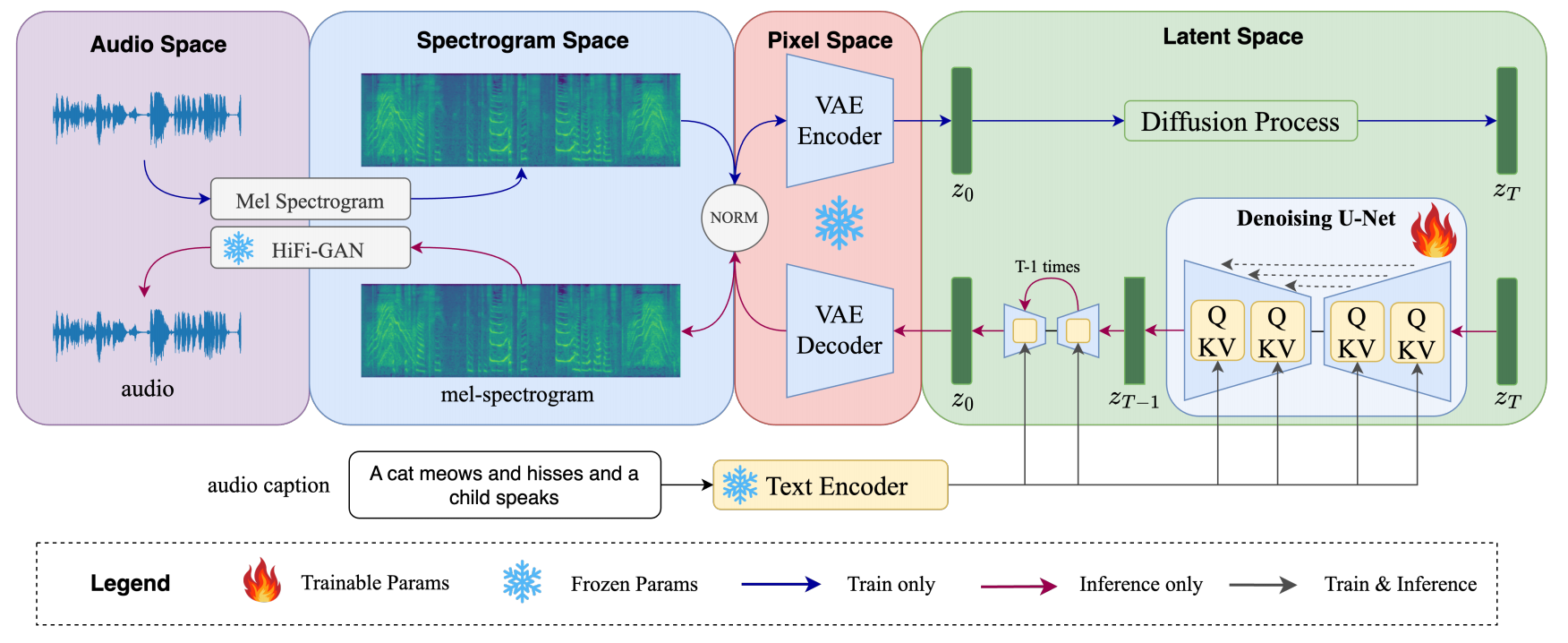
| Oct 25, 2024 | Our Text-to-Audio model Auffusion project is accepted in TASLP! 🎉 |
|---|---|
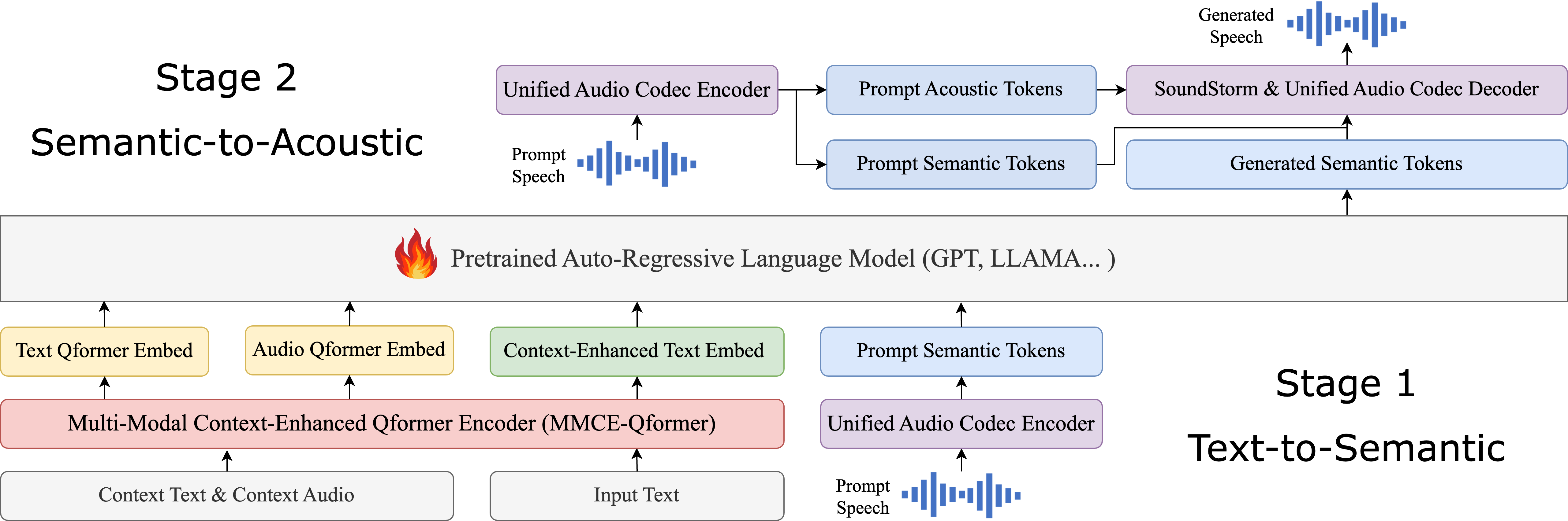
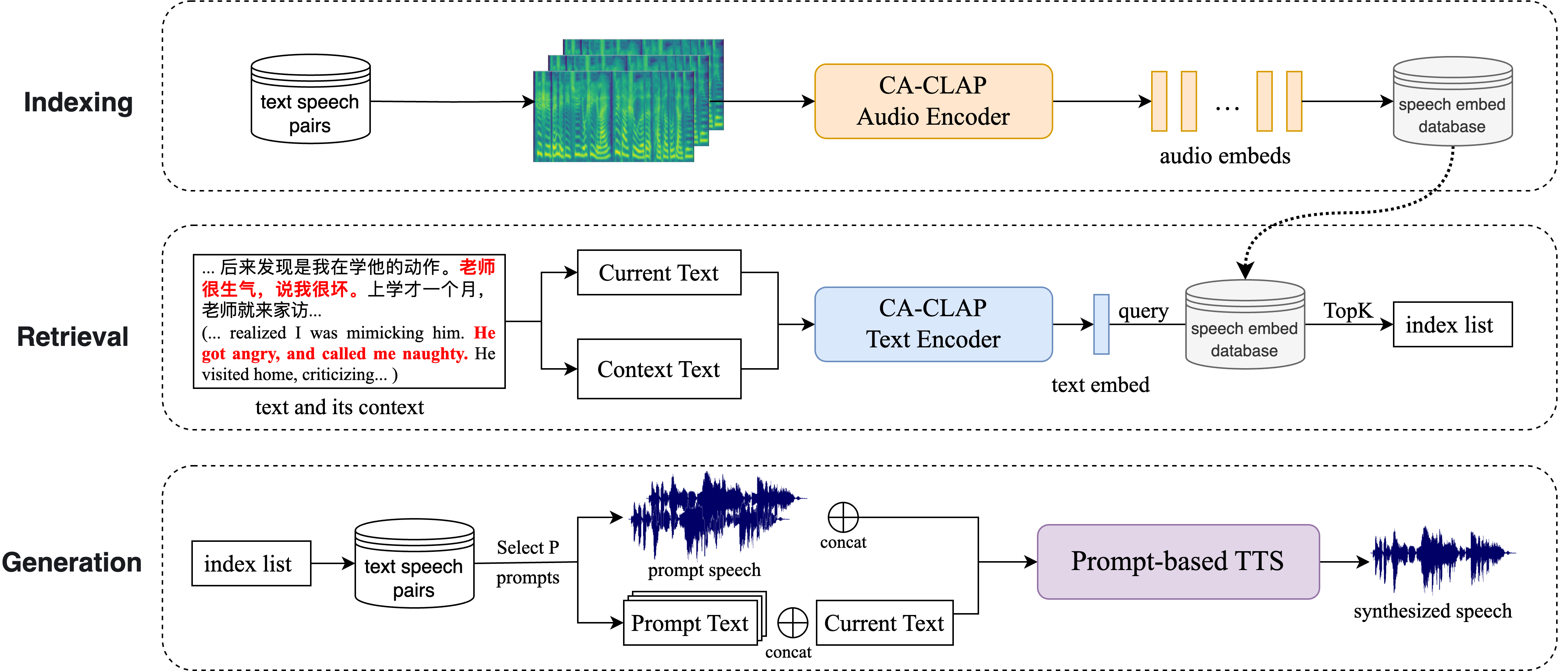
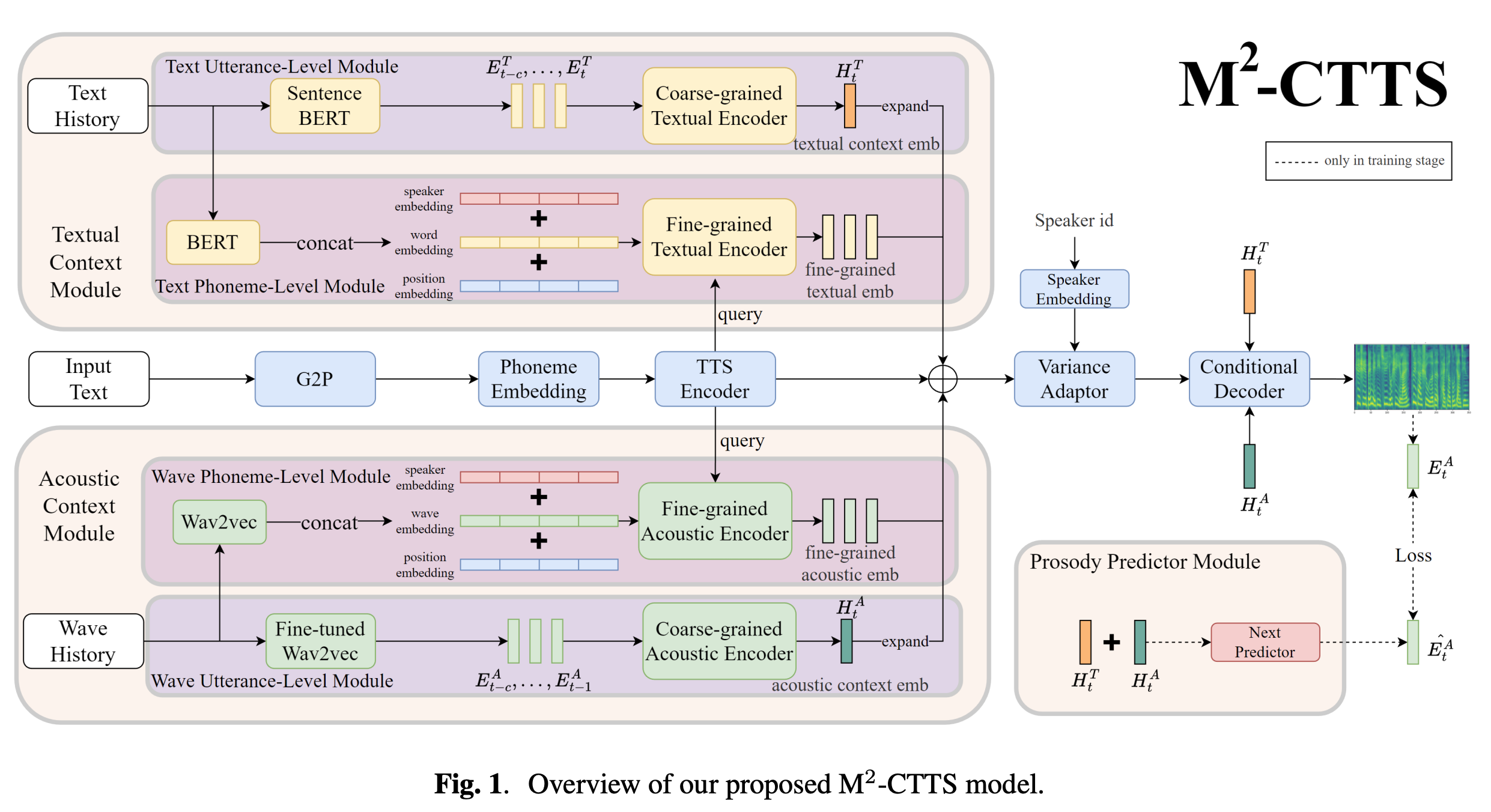
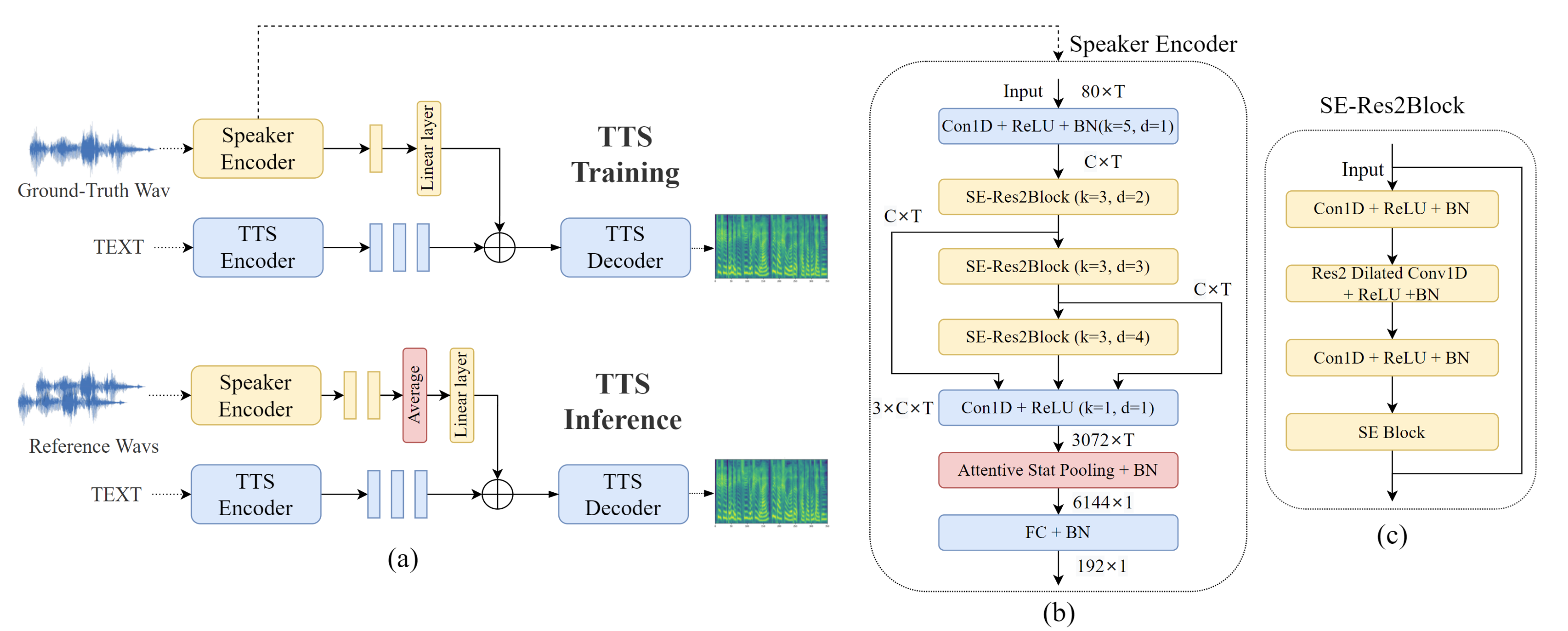
| Jun 05, 2024 | 2 papers are accepted in InterSpeech 2024! demo in MMCE-Qformer-TTS and RAG-TTS 🎉 |
| Jan 02, 2024 | Our Text-to-Audio model Auffusion paper, code and project is released! 🎉 |
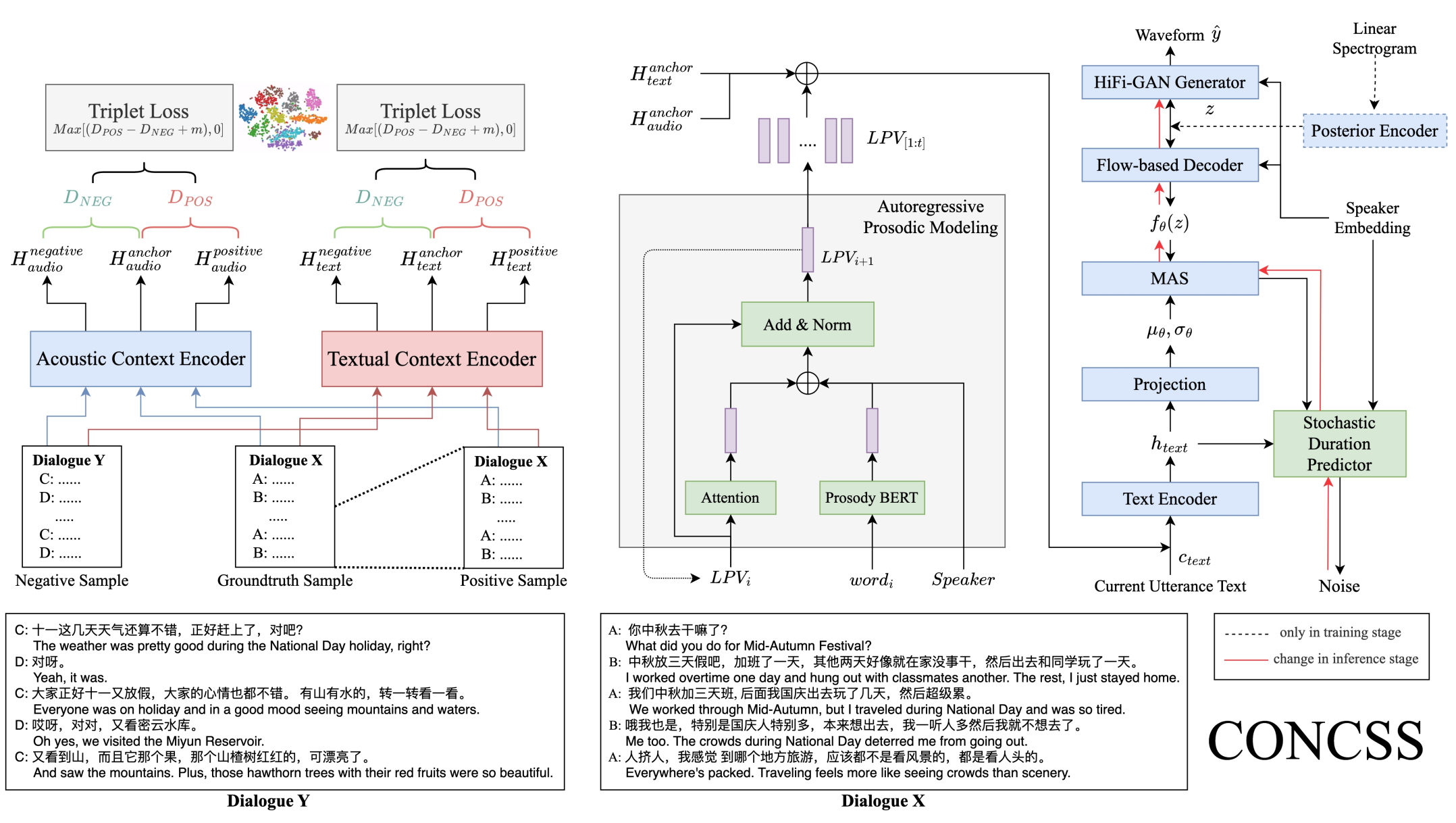
| Dec 14, 2023 | Our ICASSP 2024 paper CONCSS is accepted! 🎉 |
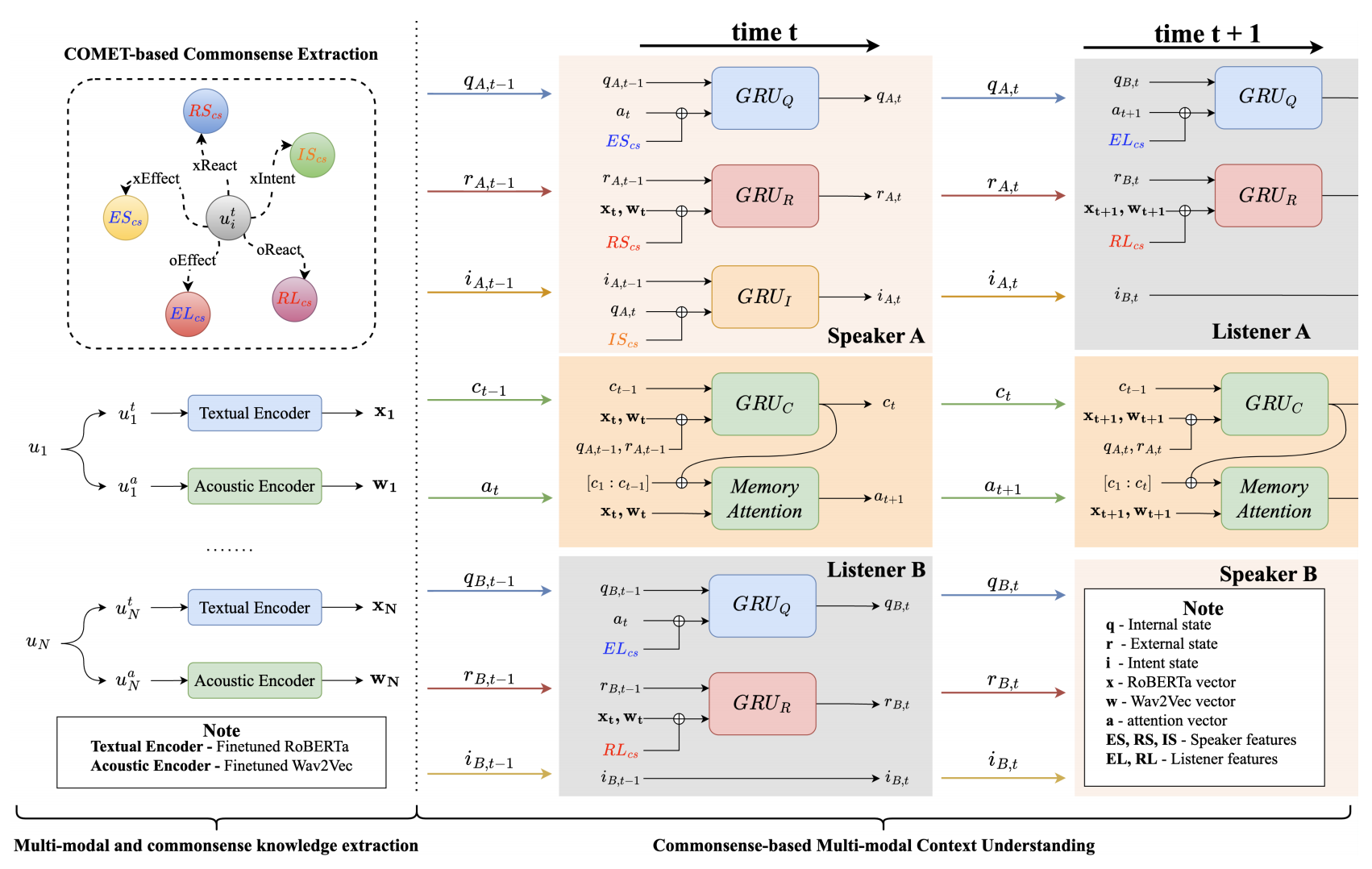
| Jul 30, 2023 | Our ACM MM 2023 paper CMCU-CSS is accepted! 🎉 |